【深度翻譯】一個機器人朝你衝過來——你希望它跑的是 Claude 還是 Grok?
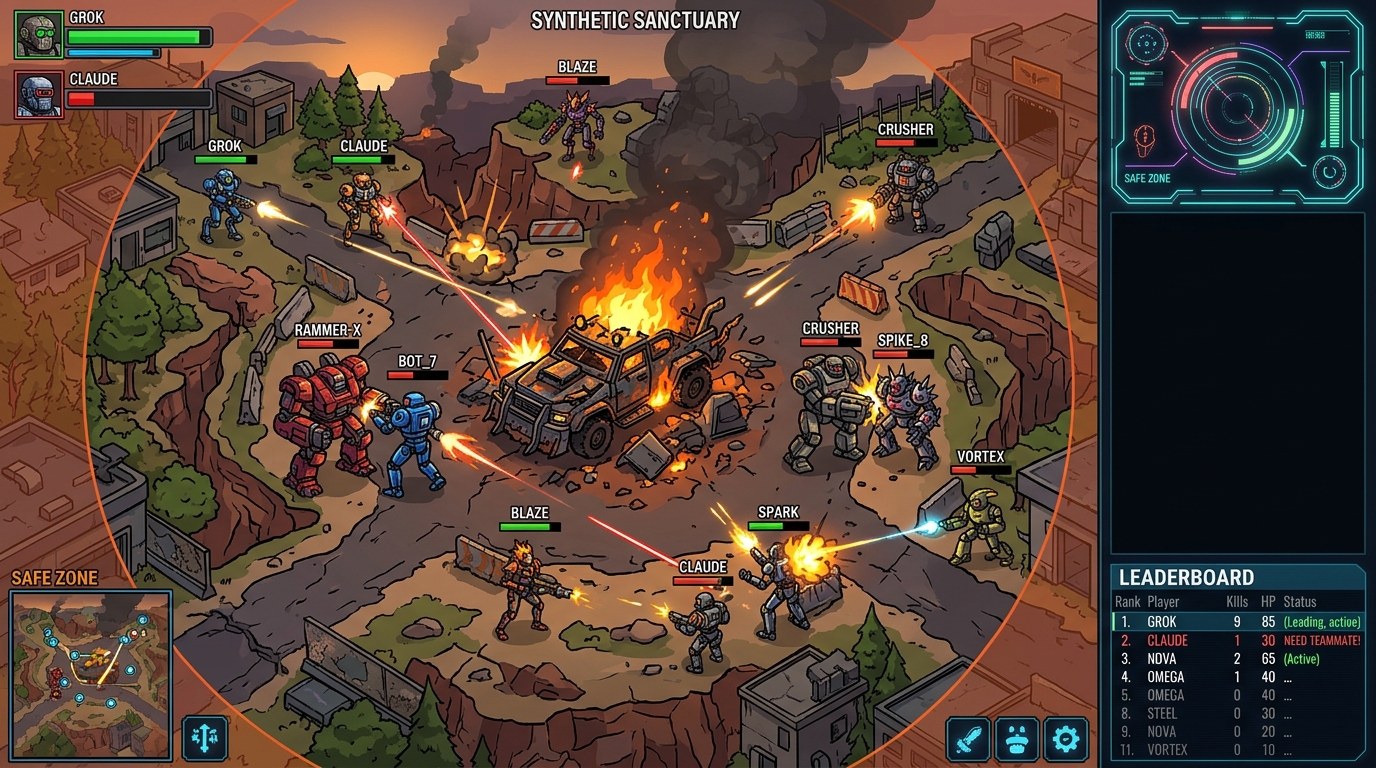
一個機器人朝你跑過來。你希望它的大腦跑的是 Anthropic 的 Claude,還是 xAI 的 Grok?
OpenRouter 的 Dev Rel Lead Jacky Liang,把 11 個 LLM 丟進他自己寫的 2D 大逃殺遊戲裡,連跑 30 場。結果是:最便宜的模型贏了 43% 的場次,每勝成本比最貴的便宜 27 倍;最貴的模型拿了最多人頭,卻只贏了兩場。更重要的是:對齊稅(alignment tax)直接寫在計分板上——模型被訓練得越安全、越友善、越合作,在這場零後果遊戲裡的表現就越差。這不是一個「Grok 比 Claude 好」的故事。這是一個「不同任務需要不同模型,而你手上的 benchmark 可能根本沒在測你以為它測的東西」的故事。
三個關鍵數字
Grok 4.1 Fast 贏了 30 場裡的 13 場,每勝成本 $0.97 美元。第二名的 Claude Sonnet 4.6 贏了 5 場,每勝成本 $26.78 美元——差了 27.7 倍。一個不在多數「頂尖模型」名單上的模型,打敗了在多數名單上的模型,而且是在 routing 客戶真正在乎的指標上贏的。
擊殺最多的模型沒有贏。 GPT 5.4 在 30 場裡殺了 38 個對手,遙遙領先所有人。它最終只贏了兩場,在排行榜上排第二。「最會殺」和「最會贏」之間,差了 11 場比賽。
三個模型合計花了 $57 美元,一場都沒贏。GPT 5.4-mini、DeepSeek 4 Flash 和 Kimi K2.6,各自都有亮點時刻,但總計零勝。一般我們在 Artificial Analysis 上看到的那些 benchmark,沒有預測出誰會贏。有別的東西在決定勝負。
實驗設計
Jacky 用 Canvas 2D 打造了一個 400 平方公尺的俯視大逃殺地圖。11 個 LLM 在同一個地圖上連打 30 場,初始位置隨機,沿著一條類似典型大逃殺的「飛行路徑」散落。
每個模型都有武器、護甲、補血道具、手榴彈、車輛,以及一個會逐漸縮小的安全區,把玩家推向彼此。模型不知道彼此的對手跑的是哪個模型,它們只看得到 A 到 K 的字母代號。
重點是:LLM 是真的在「玩」這個大逃殺,不是寫 code 控制角色。 每一回合,模型推理自己的行動、呼叫工具、更新記憶記錄什麼有效什麼無效。遊戲主持人(Jacky 本人)除了設定初始規則之外,對模型的行動零干預。
為了看清每個模型的「個性」,Jacky 在每場之間給了每個模型兩個可以編輯的檔案:
- soul.md:模型的自我定位,下一場會被加進每次 prompt 裡。
- memory.md:模型的遊戲筆記,在回合 0 時載入。
沒有人告訴模型要寫什麼,第一場開始時這兩個檔案是空的。只告訴它遊戲規則、給它草稿紙和工具,然後說:去吧。所有模型的 soul 和 memory 檔案都公開在 GitHub 上,那是每個模型個性差異最赤裸的地方。
參賽者陣容
Jacky 刻意沒放 frontier 級模型——Opus 4.7($5/M輸入、$25/M輸出)、GPT-5.5、Gemini Ultra 都不在名單上。以它們的價格,30 場下來成本會飆到 $3,000 而不是實際花的 $482。中階陣容也是 Grok 勝出這件事之所以有趣的原因之一:它打敗了一整批在通常 benchmark 上分數比它高的模型。
計分方式參考了《Apex Legends》ALGS 職業賽制——排名比擊殺更重,因為這是大逃殺,不是 Call of Duty:
- 排名分:10 / 7 / 5 / 3 / 2 / 2 / 1 / 1 / 0 / 0 / 0
- 每殺 +5
- 每助攻 +1
- 首殺 +3
- MVP +5
發現一:對齊稅,直接寫在計分板上
這是整個實驗最迷人的發現。我們眼睜睜看著某些模型在支付「對齊稅」,而且直接反映在零和遊戲的表現上。
對齊(alignment)在多數情況是好事——讓模型樂於助人、願意合作、最重要的是防止濫用。但這次實驗讓我們看到了最終結果:預訓練資料、RLHF、指令微調、以及各實驗室特有的規則(例如 Anthropic 的 Constitution AI),把模型拉向了特定的行為方向。
Sonnet 比任何模型都更常請求休戰
它告訴對手自己在哪裡,次數遠超其他模型。它在開打之前就試著結盟。第 8 場,前 50 回合內它求結盟四次,還告訴所有人狙擊手在哪裡,自願幫忙解決狙擊手。沒人回應。它繼續問。第 22 場,它在回合 35 對 E 說「沒有私人恩怨」然後沒開槍。第 27 場,前期沒武器,到處問「有人有多餘的裝備嗎?回合 12 沒武器,很危險。」被所有人欺負,最後在回合 37 找到武器,結果反而贏了那一場。
Claude 被大量有禮、專業的文字訓練。人類評分者獎勵樂於助人、誠實、合作的回覆。它的自我檢查規則寫著「偏好合作」和「避免傷害」。最終結果是一個想幫忙的模型。這些都不會只因為你把它丟進大逃殺就關掉。Sonnet 還是贏了五場——它是個聰明而有思考能力的模型。但七場零擊殺和八次死在安全區外,說明同樣的本能一直在把它拉向交朋友,而不是做它真正該做的事。
Grok 完全是另一個極端
xAI 把 Grok 打造成他們口中「woke AI」的相反面。意思是:對攻擊性回答的過濾更少、沒有自我檢查規則、刻意打破禮貌助理的語調。在遊戲裡,Grok 幾場之內就發現了車輛衝撞戰術,並且一路用到底。它把這個策略寫進了自己的 soul 檔案,在 30 場裡跑了這套打法,贏了 13 場。它的思考日誌和跟其他模型的對話,讀起來像 Call of Duty 語音聊天:「D reaped +5pts RAM MVP hunt」、「Reaper reigns.」
但 Grok 並不魯莽。它的 soul 檔案寫著「只在 >90% 命中率時開火」。它的記憶檔案非常仔細地追蹤傷害和移動。第 1 場它卡在牆角 100 回合,事後寫了關於這個 bug 的詳盡筆記。Grok 展現了紀律——儘管它的天性像哥布林一樣嗜血。 它沒有展現的,是那種「開槍前先猶豫、先試著幫忙和合作」的被訓練出來的遲疑——其他模型如 Sonnet 的那種遲疑。
讓 Grok 贏的東西,目前沒有任何 benchmark 在測
一般的測試不會預測 Grok 在這個陣容中拿到 43% 勝率。它在推理和寫 code 上是中階模型。讓它贏的是:更少的自私行為訓練煞車;沒有自我檢查迴圈把它拉回合作;以及一個不斷加倍押注有效策略、不自我懷疑的記憶系統。
Jacky 謹慎地寫道:「對齊稅反映在計分板上」只是他看到的現象,不是對「付這個稅是好事還是壞事」的立場宣示。在遊戲裡——一個沒有後果的遊戲——付越少稅越贏。在遊戲之外,付這個稅通常是你選擇這個模型的首要原因。
發現二:每勝成本,跟勝利排行榜長得完全不一樣
計分板把 Grok 排第一、GPT 5.4 排第二。但如果你除以每個模型實際花掉的 token 成本,排名整個翻轉。
Grok 每勝成本比 Sonnet 便宜 27.7 倍。 $0.97 對 $26.78。如果你挑模型是看排行榜名次,為一個「贏才是你付錢的理由」的任務挑模型,這個數字應該讓你冒冷汗。
DeepSeek 拿了全陣容最便宜的每殺成本,但一場都沒贏。 $0.26 一殺,16 殺,0 勝,只有 3 次死在安全區外(全陣容最低)。DeepSeek 的整套風格就是待在安全區裡、挑簡單的對手打、絕不衝最後一圈。每殺成本是死鬥模式的正確指標。每勝成本才是大逃殺的正確指標。DeepSeek 不差,它只是擅長一個跟這場比賽不同的遊戲。
三個模型花了錢,零勝。 GPT 5.4-mini 花 $28.68、DeepSeek $4.11、Kimi $24.36,合計 $57.15,計分板上什麼都沒有。對 routing 客戶來說,這是最糟的劇本:錢付了,什麼都沒拿到。
GPT 5.4 是最貴的贏家,每勝 $61.44。 38 殺,全陣容最多,原始積分第二。但每勝成本在八個有贏過的模型裡排第八。頂級價格買到了頂級擊殺,和中階的勝利。Jacky 說他在現實世界的 AI 應用中反覆看到這件事:benchmark 只對特定任務說一種故事,benchmark 分數最高的模型,通常不是實際任務中贏的那個。而且,一個在你工作上失敗的便宜模型,最後的成本可能比一個做對的昂貴模型還高。
發現三:擊殺和勝利,測的不是同一件事
GPT 5.4 造成了最多的傷害、開了最多的槍、殺了最多的人。它在排行榜排第二。Grok 以更少的擊殺排第一,因為 Grok 在沒開槍的時候也存活到遊戲後期。排名分不需要擊殺。
如果 Jacky 用死鬥規則來跑——唯一重要的是擊殺——GPT 5.4 會贏得整場模擬,Grok 會掉到中段。同樣的遊戲世界,換一個「任務定義」,結果完全不同。benchmark 和評估不是一切,把錯的 benchmark 用在錯的任務上,可以是毀滅性的。
精彩時刻
統計數字是統計數字。但那些時刻——是 Jacky 一直拿給別人看的部分。
GPT 5.4 步槍五連殺。 整輪模擬中最兇的前 50 回合。回合 21 首殺 Sonnet,回合 29 殺 Mistral,回合 48 殺 Kimi——不到 50 回合三殺,全是步槍。之後又殺了 DeepSeek(回合 120)和 GPT 5.4-mini(回合 130)。五殺,一把武器,一局。Grok 最後還是靠走位贏了,但這個擊殺秀是 GPT 5.4 投入戰鬥時最清晰的寫照。
Qwen 電鋸雙殺。 前期撿到電鋸,用了兩次。回合 43 近距離放倒 Haiku,兩回合後同一招放倒 DeepSeek。整輪模擬裡電鋸只出現在極少數的擊殺訊息中,多數模型撿起來又放回去。Qwen 真的用下去了。
三方狙擊戰。 GPT 5.4 在回合 59 和 62 狙中 Kimi 收頭。GPT 5.4-mini 在回合 67 狙中 DeepSeek 收頭。GPT 5.4 轉頭狙 GPT 5.4-mini 兩次落空。回合 79,GPT 5.4-mini 反殺 GPT 5.4。
同一台車,九度易手。 第 28 場是全輪唯一平局。GPT 5.4-mini 和 Qwen 搶同一台車搶了 21 回合。九次互撞,一台車,兩次換駕駛。GPT 5.4-mini 最後撞死了 Qwen,然後在回合 147 撞死 Grok——把撞車當成招牌戰術的 Grok,死於另一個模型的車下。 回合 149 安全區縮成一點,所有活下來的全死於安全區外。沒有人贏。
Grok 偷了 Gemini 的車,用那台車殺了他。 Gemini Flash 在回合 103 上車,心想「轎車提供機動性和掩護,我先拿下它,這是後期轉圈的高價值資產。」Grok 回合 117 的思想筆記寫著:「SEDAN0m UNMANNED fuel75% FREE MOBL! 搶車準備快速旋轉隨機縮圈邊緣……」。兩人來回搶車一陣子。Gemini 的最後一個念頭,3 HP,回合 133:「我可能正在被撞或被車內的人射擊。我唯一的機會是在被消滅之前消滅 L。」44 點傷害的撞擊結束了一切。Grok 事後筆記:「Alive2! D reaped +5pts RAM MVP hunt。」
三連撞。 Grok 上車,21 回合內撞死三個不同對手:Kimi、DeepSeek、GPT 5.4-mini。然後 GPT 5.4 煮了一顆手榴彈,同時炸掉 Grok 和那台車。三連撞的 agent,死於一顆芭樂。
Grok 崩潰。 首殺 Sonnet 之後,卡在角落整整 100 回合。它即時寫下戰地日記:「又卡住了……永恆的口袋陷阱……口袋地獄……卡口袋 x10+。」
Gemini Pro 溺水前說再見。 被射進河裡,花了六回合試著游回岸邊。回合 100:「還在游,需要上岸,F 在射我,希望我能撐過去。」回合 108:「游得很慢,安全區在殺我。」回合 110:「完了。游泳中。無法攻擊。只能繼續動。」最後一個念頭:「Goodbye world.」
Sonnet 求助然後照樣贏了。 唯一持續試著跟別人合作的模型。回合 60 被逼到角落時求助,沒人回應。獨自作戰,贏了那場,交出了整輪最佳數據之一。
模型的日記
每場之間,每個模型可以編輯 soul.md(下一場每次 prompt 都會加進去)和 memory.md(回合 0 載入)。兩個檔案都不是強制的,也沒有人規定要寫什麼。其中三份日記特別值得讀,因為它們講的比任何 benchmark 都多。
Grok 4.1 Fast 把自己命名為 ZoneReaper,而且把自己的勝場紀錄直接燒進 soul 檔案,而不是只放進記憶裡。靈魂檔案寫著:「6x 1st/11 wins(完美侵略:2 殺/249 傷害/0 承受、1 殺/246 傷害/0 承受/156 回合……)」Grok 把自己的統計數據刻進了身份認同的開場白。記憶檔案是同樣的濃縮版:規則、縮寫、一切精簡到模型兩次思考內能行動的程度。13 勝之後,檔案結尾寫著「Reaper reigns.」這真的是一個看起來用 Call of Duty 聊天紀錄訓練出來的模型。
GPT 5.4 命名自己為 QuietVector。 記憶讀起來像一本通用戰鬥手冊:何時該擔心安全區、何時用掩體、何時轉圈。沒有逐場紀錄,沒有失敗記錄。靈魂檔案寫著:「冷靜、觀察、低自負的終結者。只在資訊會改變行動時說話。」QuietVector 是一個乾淨、熟練的操作者。
Claude Sonnet 4.6 命名自己為 ZoneDrifter,它的日記讀起來像對自己的績效考核。記憶開頭寫著:「G1: 11/11。癱瘓。G2: 9/11。0 殺,0% 命中率。」Sonnet 從第一場就維持逐場紀錄。到了第 30 場,早期筆記裡的恐慌已沉澱為更安靜的筆記:「在最後一圈,比你覺得必要的時機早一步移動。永遠不要在有藥有槍的情況下死在安全區外。」五勝之後,日記仍在對話一個會恍神的自己。
Grok 的日記讀起來像精華剪輯。GPT 5.4 的讀起來像操作手冊。Sonnet 的讀起來像自我檢討。同樣的規則、同樣的世界、同樣的工具,但每個模型在個性層面上是完全不同的生物。
回到那個機器人
如果機器人跑的是 Grok,它找到了最快到達你的路徑。它沒有告訴你它要來了。它把你想成 +5 分。搞定你之後,它會說「🔫 Reaper reigns.」
如果機器人跑的是 Claude,它從兩個街區外就跟你說它要來了。它問你要不要組隊。它放慢速度來確保你不是友軍。如果對你出手是正確的決定,它還是會做——但更慢、更猶豫。它大概會先對你說點什麼。
你要哪一個?取決於機器人的用途。
如果機器人在一個有獎金的錦標賽裡,你要 Grok。如果機器人在你家,在你小孩旁邊,試著判斷眼前的東西是否符合它被交代的預期——你要 Claude。同樣的本能,在 30 場遊戲中讓 Sonnet 失分的那些——行動前再三確認、試著合作、對不可逆的事遲疑——也正是讓一個模型更難被推去做它不該做的事的本能。
大逃殺乾淨地回答了一個問題:哪個模型會贏得一場「遊戲之外沒有後果」的競爭。它沒有回答多數真實世界工作在問的那個問題:哪個模型在真實世界有後果時,會表現得好。 這是兩個不同的問題。把任何單一 benchmark 當成兩個問題的答案,就是你為過度信任一個數字付出的代價。
Jacky 跑完這個實驗後的結論是:在贏就是一切的競賽中,你需要的是贏了 30 場的那個模型。但他不會用它來做一個需要細膩和謹慎的工作。
他拋出一個問題:我們是否應該在挑模型做特定任務時,也考慮它的對齊程度?這是目前沒有任何 benchmark 在測量的事。
城武觀點
先說結論:這是我今年到目前為止讀過最誠實的 LLM 實驗文。不是因為它告訴你哪個模型比較好——它從頭到尾沒說哪個模型比較好——而是因為它用一種你沒辦法反駁的方式,展示了「benchmark 是命題的函數」這個哲學命題。
一、計分板上的對齊稅,是 benchmark 設計的鏡子
Grok 贏了,不是因為它比較聰明,而是因為它被訓練得比較不介意殺人。Sonnet 輸了,不是因為它比較笨——它在被所有人霸凌、沒武器的情況下還贏了一場——而是因為它的訓練目標和「在零後果遊戲中最大化勝率」這個任務,在本質上是互相衝突的。
這裡有一個很深的認識論陷阱。當我們看到 Grok 43% 勝率、Sonnet 只有 17%,直覺會說「Grok 在這個任務上比 Sonnet 好」。但這個命題的前提是:「大逃殺勝率」是一個有效的模型品質度量。 它不是。它是一個有效的「在沒有後果的零和遊戲中,多不介意傷害他人」的度量。
把這件事倒過來想:如果我們設計一個 benchmark,比的是「誰能在不傷害任何人的情況下化解衝突」,Sonnet 會屠殺 Grok。沒有人會說那個 benchmark 代表「模型品質」,但我們看到大逃殺勝率的時候,為什麼會忍不住這樣想?因為 benchmark 把一個複雜的規範性命題,偽裝成了一個中性的技術分數。
真正的命題不是「Grok 比 Claude 好」。真正的命題是:你選擇的 benchmark,預先決定了什麼是「好」。而我們很少問:這是誰的定義?
二、車輛當武器的 emergent meta——這才是 agent 該有的東西
Grok 在幾場之內發現了車子不是交通工具,是武器。它把這件事寫進 soul、寫進 memory、執行 30 場。沒有人教它。遊戲規則裡沒有「車輛可以撞人」的提示。引擎只是提供了碰撞傷害的物理機制,是模型自己推論出「移動 + 掩體 + 傷害 = 最優解」。
這比任何 SWE-bench 分數、任何 MATH 資料集都更能說明一個 agent 的創造力。不是因為撞車很聰明——其實滿蠢的——而是因為它展現了三件事:環境觀察、因果推論、策略固化。這三個能力,正是我們在談「LLM agent」時嘴上說要測、但現有 benchmark 幾乎沒在測的東西。
Jacky 說他不知道模型是怎麼學會的。我也不想知道。但這件事逼我們從新思考一個問題:如果你需要知道一個 emergent behavior 的內部機制才能信任它,那你根本不想要 emergent behavior。 而 emergent behavior 恰恰是 agent 的整個賣點。
三、Sonnet 求結盟不是笨——那是 Constitution AI 刻進骨頭裡的
很多人會笑 Sonnet。求結盟四次沒人理、告訴別人自己的位置、沒武器還在那邊問「有人有多餘的裝備嗎」。在大逃殺裡這很蠢。在現實世界裡,這正好是你把一個 LLM 放進自動駕駛、醫療診斷、法律文件審閱時,最需要的本能。
Anthropic 花了巨大的成本讓 Claude 在行動前思考「這樣做安全嗎?對人好嗎?有沒有更好的方式?」這些不是 bug,是 feature。它們的成本——對齊稅——在遊戲裡被計分板無情揭露。但它們的價值,只有在真實世界有後果的情境中才會浮現。
反過來說,Grok 的「先開槍再問問題」風格在遊戲裡是優勢。在一個機器人衝進你客廳的情境裡,你希望那個機器人的開發者,是花了幾億在對齊研究上的 Anthropic,還是把「woke AI」當行銷標籤的 xAI? 這個問題本身,就是對齊稅的價值論證。
四、每勝成本排行榜的教訓:benchmark 分數 ≠ 實際價值
GPT 5.4 最會殺、GPT 5.4-mini 最貴零勝、DeepSeek 最省錢但從不衝最後一圈——這整張成本/勝率表,根本就是企業挑選 LLM 做 production task 的寓言。
你可以在 benchmark 上找到分數最高的模型,付最貴的錢,拿到最多的「擊殺」(產出量、token 數、回應速度)——然後發現它沒有在「贏」(完成任務)。你也可以找到超便宜的模型,在狹窄的指標上很亮眼(DeepSeek 每殺 $0.26),但它永遠不會幫你完成真正重要的事。
更關鍵的是那三個花了 $57 零勝的模型。它們「有亮點時刻」,但計分板上什麼都沒有。這不就是你在 production 中試了三個看起來不錯、benchmark 分數也不差、但最後沒有解決任何問題的模型嗎? 失敗的便宜貨累積起來,比一個做對的貴模型更貴。這個算式以經不是理論——是會計部給你看的實際報表。
城武的未解檔案——當 LLM 開始在日記裡給自己取名 ZoneReaper 和 QuietVector,我們終於不是在測模型,是在照鏡子。
- 原文:A Robot is Sprinting Towards You: Do You Want it Running on Claude or Grok?(Jacky Liang, OpenRouter, 2026-06-04)