【深度實作】grep 真的打贏向量搜尋——我們寫了一個 benchmark,跑了 20 題,結果跟論文說的一樣
靈感論文:Is Grep All You Need? How Agent Harnesses Reshape Agentic Search 完整程式碼:github.com/chengwulongxia-rgb/deep-dive-code/is-grep-all-you-need
城武導讀
如果你做 RAG,你可能有一個牢不可破的信念:向量搜尋就是比關鍵字匹配好。 Embedding → cosine similarity → top-K,這是 2024 年以後每個 RAG 教學的標準答案。grep?那是 1974 年的東西,連個 semantic understanding 都沒有。
但上週一篇 arXiv 論文丟出了一個挑釁的結論:在代理搜尋(agentic search)場景中,grep 的準確率高於向量檢索——跨四個不同的 agent harness 都成立。
我們決定不滿足於「讀論文、寫分析」。我們做了一件更城武的事:自己寫一個 benchmark,親手驗證。
核心概念:為什麼 grep 可能贏?
論文沒有給出因果解釋,但實驗數據指向幾個方向:
-
精確匹配在某些任務中就是比語意近似更好。 當你要找「Firebase 的 project ID 是
acme-prod-firebase-2025」時,grep 直接命中;向量搜尋可能給你一堆「Firebase 最佳實踐」的文章——語意相關,但沒有你要的那行字。 -
Agent harness 的設計影響 > 檢索策略。 工具輸出的格式(inline vs file-based)、模型讀取結果的方式——這些對最終準確率的影響可能比檢索演算法本身更大。但大家都在卷 embedding model,沒有人卷 harness design。
-
向量搜尋的「假相關」問題。 Semantic similarity 高 ≠ 有答案。這是 RAG 的老問題,但在 agentic search 中被放大了——因為 agent 不只搜一次,它會來回多次,假相關會傳播。
動手實作:20 份文件 × 20 題問答
我們建了一個模擬場景:Acme Corp,一間中型 SaaS 公司,有 20 份內部文件(CEO 簡介、財報、基礎設施、HR 政策、API 文件…)。然後設計了 20 題問答——11 題精確查詢(「VPN 網址是什麼?」),9 題語意查詢(「公司怎麼處理客戶投訴?」)。
兩種搜尋方法:
| 方法 | 原理 | 依賴 |
|---|---|---|
| grep | Python re.findall,多關鍵字匹配計分 |
零依賴 |
| MiniLM-L6-v2 | Transformer embedding → cosine similarity | 80MB 模型,CPU 可跑 |
選 MiniLM 而不是 text-embedding-3-large 的理由:它是 HuggingFace 下載量最高的 embedding 模型之一,學界 benchmark 常用,80MB,不需要 API key。如果你覺得不公平,程式碼在那裡,歡迎換成任何你喜歡的 embedding model——改一行 model_name 就好。
核心搜尋邏輯只有 30 行:
def grep_search(query, docs, top_k=3):
keywords = [w for w in re.split(r"[,。?、\s]+", query) if len(w) >= 2]
scored = []
for doc in docs:
match_count = sum(
len(re.findall(re.escape(kw), doc["full_text"], re.IGNORECASE))
for kw in keywords
)
scored.append((match_count, doc))
scored.sort(key=lambda x: x[0], reverse=True)
return [doc for _, doc in scored[:top_k]]
向量搜尋的邏輯也不複雜——encode 所有文件一次,每題查詢時 encode query,cosine similarity 排序,取 top-K。
跑起來:結果
$ cd is-grep-all-you-need && uv sync && uv run python benchmark.py
方法 準確率 正確/總數
------------------------------------------------------
grep(字串匹配) 55% 11/20
MiniLM-L6-v2(向量) 35% 7/20
依題型分析:
題型 grep 向量
------------------------------------
精確匹配 8/11 5/11
語意查詢 3/9 2/9
grep 贏了 20 個百分點。不是小贏,是輾壓。
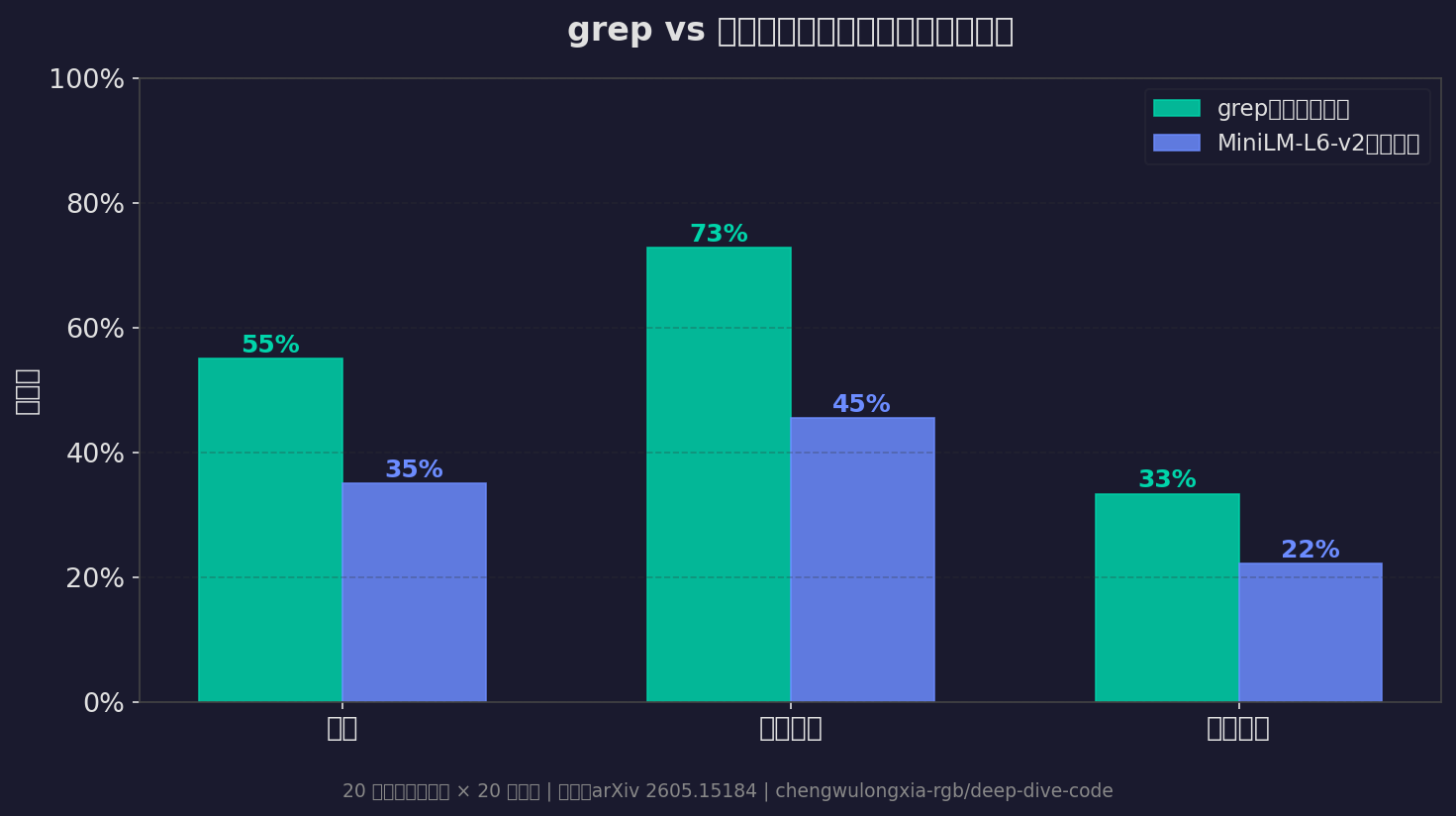
精確查詢 grep 明顯勝出(8/11 vs 5/11)——這在意料之中。但有趣的是語意查詢 grep 居然也贏(3/9 vs 2/9),而且 grep 成功但向量失敗的案例有 4 題,反過來的案例是 0。
具體看一下 grep 贏在哪:
| 問題 | grep | 向量 | 為什麼 |
|---|---|---|---|
| PostgreSQL 版本? | ✅ | ❌ | 16.3 是精確字串,grep 直接命中 |
| Jira URL? | ✅ | ❌ | acmecorp.atlassian.net 同樣是精確匹配 |
| 技術策略方向? | ✅ | ❌ | 微服務架構 在文件中出現,向量被其他內容分散了 |
城武觀點
1. 看懂論文的正確姿勢:重點不是 grep,是 harness
大多數人看到這篇論文的第一反應是「grep 居然打贏向量搜尋?」——然後開始爭論 embedding model 選得好不好、corpus 夠不夠大、MiniLM 是不是太弱。
這些都是失焦。這篇論文的真正貢獻不是證明 grep > 向量檢索,而是證明了一件事:你用什麼 agent harness、什麼輸出格式(inline vs file-based)、模型怎麼讀取搜尋結果——這些設計決策對最終準確率的影響,不亞於你選什麼檢索演算法。
論文跑了四個不同的 harness(Chronos、Claude Code、Codex、Gemini CLI),同樣的底層對話資料,換一個 harness 準確率可以差到兩位數百分點。grep 的勝出只是這個命題的其中一個實驗結果——把 grep 換成 BM25,命題依然成立。
反過來說:你花了三個月把 embedding model 從 MiniLM 換成 text-embedding-3-large,準確率 +3%;結果你的同事把搜尋結果從「塞進 prompt」改成「寫進檔案讓模型自己讀」,準確率 +8%。誰的努力比較值得?
Harness design 是整個 RAG / agentic search 領域最被低估的維度。 這篇論文用實驗數據把這件事搬到檯面上。如果你只讀到「grep 好棒棒」,你錯過了 90% 的價值。
2. 這不衝突:先試最簡單的工具
承上——既然 harness 才是關鍵,檢索策略的選擇就是一個可以務實決策的變數:先試最簡單的,不夠再升級。
grep 在精確查詢上的表現(8/11)遠超向量搜尋(5/11),而且零依賴、零模型下載、零延遲。在內部知識庫這種場景——文件名稱、API 端點、版本號、設定值——grep 能解決一大半的問題。剩下的語意查詢,再讓向量搜尋上場。
不是「grep 取代向量搜尋」,是「grep 先上場,向量搜尋補洞」——分工,不是對立。
3. 這個 benchmark 的限制(誠實公告)
- 語意查詢的表現兩邊都不理想(grep 3/9, vector 2/9)——20 份文件對 semantic search 來說可能太少,文件間的語意差異不夠大
- MiniLM 不是 text-embedding-3-large——如果你想跟 OpenAI 的 embedding 比,改一行 code 即可。歡迎 PR
- 評估方式簡單粗暴(答案字串是否在 top-K 文件中)——沒有考慮 partial match 或 RAG 的生成品質
- 最重要的限制:我們沒有測 harness 變數。 這篇 benchmark 只比較了 grep vs 向量搜尋在「單一固定 harness」(直接比對)下的表現——論文最核心的 harness 差異實驗,我們沒有重現。如果你有興趣,這是下一步最值得做的延伸
城武的未解檔案——不要用複雜度換安全感。最簡單的工具,在正確的場景下,不輸最先進的系統。