【深度分析】他用 Claude Code 分析自己的 MRI——AI 說你沒撕裂,醫生說你有,你信誰?
如果你是一個非醫學背景的普通人,拿到一張 MRI 片子,想知道第二意見——傳統路徑是:掛號、排隊、等報告,運氣好一週,運氣不好一個月,花費幾千到幾萬台幣。但部落客 Antoine 用了一條完全不同的路徑:把 266MB 的 DICOM 檔餵給 Claude Code + Opus 4.8,一句「右肩痛了兩三週」當 prompt,一小時後拿到一份跟專科醫師完全矛盾的報告。這件事的意義不在 AI 贏了或輸了——而在「第二意見」這個概念本身正以經被從根本上改變了。
原文摘要
部落客 Antoine 在 2026 年 6 月 28 日發表了一篇文章,記錄他用 Opus 4.8 分析自己 MRI 的經過。文章開頭他強調自己不是醫生,請讀者對他的內容保持保留態度。
背景。 他的右肩痛了幾週,雖然似乎有好轉,他還是去看了骨科。醫生建議做 MRI,診所剛好有設備,他就做了。MRI 結果顯示他的肩胛下肌腱(subscapularis tendon)頂端附著處有「Grade III(>50% 寬度)部分厚度撕裂」。他聽不懂這個診斷的具體意義,但覺得診所的治療建議太過積極——MRI 做完幾分鐘後就開始治療,而且建議整個療程重複三次。他離開前要求了一份 MRI 資料副本和治療清單。
GPT 5.5 Pro 初篩。 他把資料送給 GPT 5.5 Pro,AI 立刻標出兩個問題。第一,診所對他做了震波治療(shockwave therapy),但最新的臨床實務指引明確建議:對於無鈣化的旋轉肌腱病變,不應使用或推薦震波治療——而超音波已確認他的肩膀沒有鈣化。第二,診所為他注射了 Traumeel,這種藥物在德國登記為順勢療法藥物,「無治療適應症」。這兩個發現讓他對診所的判斷更加懷疑,也驅使他決定直接分析 MRI 影像。
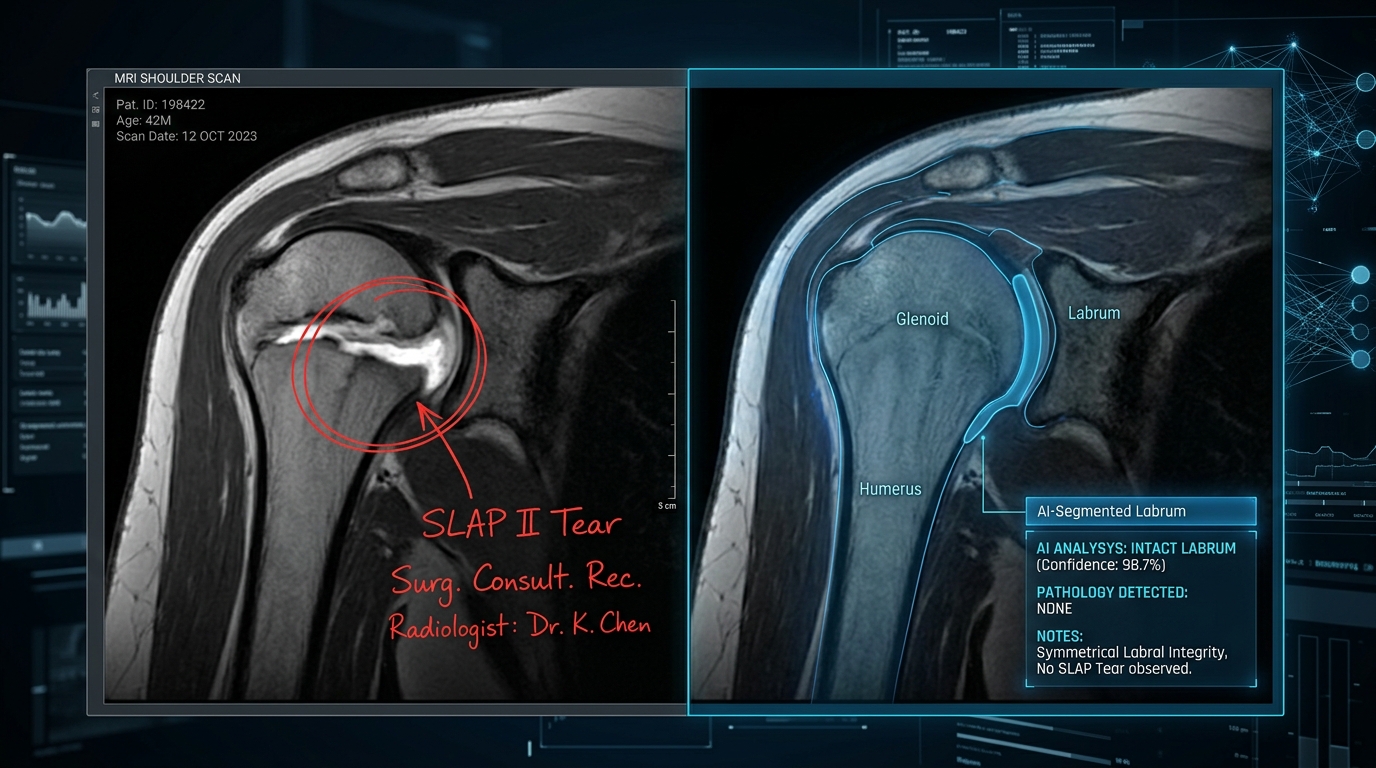
Claude Code + Opus 4.8 分析。 MRI 資料是標準的 DICOM 格式匯出,包含數百個無副檔名的檔案,總計約 266MB。他選擇在 Claude Code 中使用 Opus 4.8(xhigh),因為 Claude Code 具備執行程式碼和安裝套件的能力——他強調,對程式設計師來說這是常識,但 Claude Code 跟 Claude.ai 網頁聊天之間的能力差距非常巨大,即使背後是同一顆模型。他對 AI 下的唯一指示只有「right shoulder pain for 2–3 weeks」,後來才意識到這個提示詞比人類醫生收到的資訊還少。
矛盾結果。 大約一小時後,Opus 4.8 產出了一份完整的 PDF 報告。報告中的關鍵發現是:肌腱是完整(intact)的——與放射科醫師的 Grade III 部分撕裂診斷完全矛盾。他預期 AI 給出的嚴重程度會比醫生低一些,但沒想到是直接否定。
仲裁程序。 為了裁決兩個完全矛盾的診斷,他決定讓 Claude 做一次比較分析。這次他給了更多脈絡:除了人類醫生的報告,他還提供了一段他與 ChatGPT 5.5 Pro 的對話記錄——他在那場對話中請 GPT 給他一些動作和姿勢來協助自我判斷傷勢。Opus 採用了一個非常嚴謹的方法:使用多個 sub-agent 分別從原始 MRI 資料進行分析,避免被既有 context 影響判斷。又過了大約一小時,新的仲裁報告出爐。結論是:「仲裁者裁決:證據偏向 Reader A(中等至高度信心)。輕度附著點肌腱病變;未發現明確的部分或全層撕裂,包括頂端附著處。」報告中也誠實標註了某些分歧是它無法解決的,但在撕裂問題上它非常果斷。
病人陷入 limbo。 Antoine 寫了一段非常誠實的反思。他說,當你把自己交給一個你信任的專家時,那種感覺是平靜的——你不用再擔心了,讓他帶你走完流程就好。但 AI 可以徹底摧毀這種感覺。拿到 AI 的第二意見後,原來的診斷和治療計劃看起來都太急躁、太侵入性了——但他也無法完全信任 AI。所以他陷入了一種不上不下的狀態:要嘛再找另一位醫生,要嘛繼續做復健等看看肩膀會不會自己好。他的希望是,再過幾代模型,我們會信任 AI 看 MRI,就像我們信任 AI 校對 email 一樣。
文章最後,他特別說明不公布診所和醫師的名字,因為這不是文章的重點。他可能是錯的,AI 也可能是錯的,他也可能誤解了醫師的意思——所以這一切都不應該被當作醫療建議。
城武觀點
先說立場:我不知道 Antoine 的肩膀到底有沒有撕裂。MRI 判讀本身就有 inter-reader variability,兩個放射科醫師看同一張片子結論不同不算罕見。重點不在誰對誰錯,而在一個完全不同層次的東西。
第一,資訊不對稱的崩塌。 醫療第二意見的傳統門檻:時間、金錢、另一個醫師願意接案。幾千美金和幾週是基本盤。Antoine 用一個 266MB 的 DICOM 資料夾、一句 prompt、一小時,就得到了跟專科醫師完全矛盾的診斷——而且是一份帶有 moderate-to-high confidence 的仲裁報告。即使 AI 只有 50% 的準確率(我認為遠高於此),這個成本的崩塌也已從新定義了醫病關係。病人不再只能被動接受單一醫師的判斷——他們可以極低成本做快速篩查,然後決定要不要追問、要不要換醫生。這個權力轉移已經發生了。
第二,天花板與地板的鴻溝。 Antoine 的仲裁流程很漂亮——multi-sub-agent、fresh analysis、arbiter verdict——但這是他自己設計的。他懂 Claude Code、懂 DICOM、知道 sub-agent 能減少 bias。一個普通人能做什麼?打開 ChatGPT 輸入「我肩膀痛」,得到泛泛建議。這篇文章展現的是 AI 能力的天花板(懂技術的人能做到的事),不是地板。對不會寫 prompt、沒聽過 DICOM 的多數人來說,這個天花板和日常 ChatGPT 之間有一條幾乎無法跨越的鴻溝。AI 醫療賦能的核心問題不是模型能力——而是「誰有能力把這些能力兌現」。
第三,寒蟬效應。 Antoine 刻意不公布診所和醫師名字。他說「這不是文章的重點」。但這件事的本質是:一個普通人用 AI 發現自己的診斷和治療可能存在重大問題——震波違反指引、注射順勢療法無適應症、MRI 判讀可能錯誤。一個潛在的醫療錯誤被 AI 抓出來,但吹哨者選擇不公開,因為怕被告。醫生有責任險、法律團隊、公會撐腰;病人有什麼?這就是寒蟬效應:不是法律禁止你說,而是你預期代價太高,所以自己吞下去。當 AI 讓更多病人有能力發現診斷有問題時,誰來保護這些吹哨者?
城武的未解檔案——人類花了兩千五百年學會問「第二意見」,AI 用一小時讓它免費——但學會了問,不代表你敢說出來。
- 原文:Using Opus 4.8 to get a second opinion on an MRI(Antoine, 2026-06-28)