【深度分析】LLMs are complicated now — 當語言模型走上推薦系統的複雜化之路
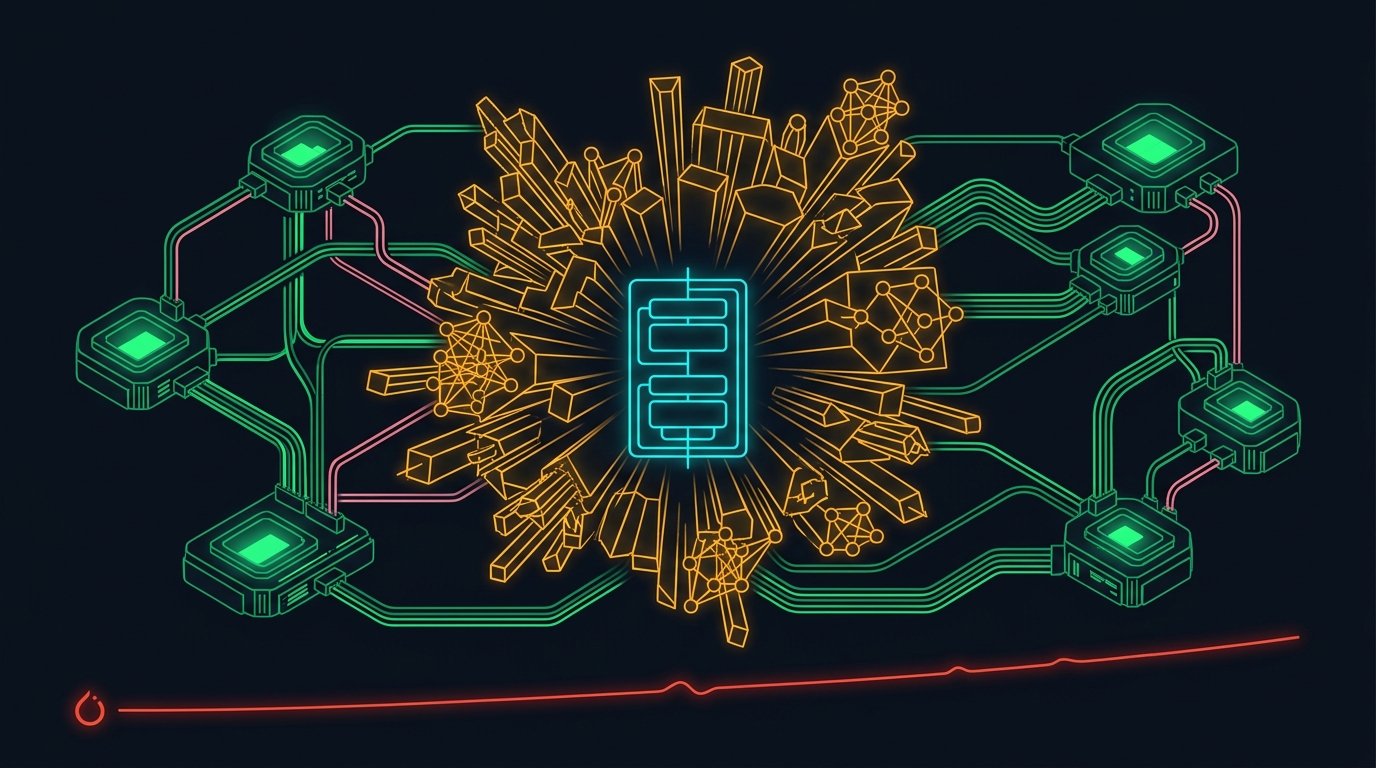
Ian Barber 從 Meta 推薦系統的歷史回望,點出一個讓人心驚的類比:2022 年的 Llama 堆疊乾淨得像教科書,2026 年的 LLM 架構已經長出 attention 變體叢林、MoE 路由增生、模態編碼器內嵌——跟當年推薦系統的技術債曲線一模一樣。這不是抱怨,而是一個架構師對「複雜度如何扼殺研究迭代速度」的冷靜診斷。
2022 到 2023 年間,Meta 內部有兩條機器學習路線同時進行。一條是催生 Llama 的 LLM 研究——乾淨、平滑的 Transformer 模組堆疊;另一條是推薦系統圖——用 Ian 自己的話說,「恐怖得嚇人」(terrifying)。如今風水輪流轉,業界成功地把 LLM 也搞複雜了。Seb Raschka 維護的模型架構圖鑑,拿來比對 Llama 3 和 Nemotron 3 Ultra 這兩世代的開源模型,差異一目了然。
Attention is all you need,但現代的模型確實用了很多不同的 attention 變體
——query grouping、compressed、sparse、linear、sliding-window,不一而足。Mixture-of-Experts 引入 feed-forward 層的選擇性路由,而現在路由已擴散到 attention block、residual stream,幾乎什麼都在路由。Vision 和 audio encoder 從「外掛」變成「內嵌」,模型則大到推論時需跨多 GPU 分切,中間塞滿通訊運算。
這跟推薦系統的歷史軌跡如出一轍。推薦系統的基礎架構過去十年本質上是簡單的雙塔稀疏神經網路,複雜度來自一個根本張力——既要持續提升能力,又要保持效率,尤其是推論效率。
有人會覺得 agent 能解決這一切:把 PyTorch 或 JAX 定義丟給 Claude Telenovela,讓它自動生成最佳化的 fused kernel。但問題是——你得先有一個固定可用的 baseline,才能確認它生成的東西是對的。推薦系統的歷史告訴我們,當「效能優化」和「效能是必要條件」之間的差距縮小到幾乎為零,麻煩就來了。理論上你可以保留純粹的模型定義當 baseline;實際上訓練和測試模型耗費大量資源,效能改善變成了承重結構。
如果你想把 attention 變體 A 換成 B,B 慢 10% 可以接受,但慢一個數量級就不行
如果 A 是經過 fused 和最佳化的,你至少需要一個部分 fused 的最佳化 B 版本,才能判斷它值不值得探索。研究迭代迴圈需要的不是單純的「最佳化這個已知變數」,而是從新思考研究需要什麼樣的彈性。你不能花大把時間手動 fused 每一條路徑,也不能沒有 baseline 就靠生成來推進。唯一的解法:從設計之初就考慮可組合性(composability)。
過去幾年我最喜歡的 kernel 開發之一,就是 PyTorch 的 FlexAttention。它透過 Triton templates 讓你可以為一整類 attention 運算生成 kernel,並且從設計上就是可組合且可驗證的——探索時對效能的影響非常輕微。
Andrej Karpathy 最近加入 Anthropic,部分目的是為了發展更完整的 auto-research 迴圈。但他過去幾年的工作也反覆證明:能夠把架構拆解到核心、讓它們可組合,跟一個聰明的 agentic setup 同樣重要。
城武觀點
Ian 懷念的「簡潔 Llama」某種程度上是集體敘事——Llama 2 已有 RoPE、RMSNorm、SwiGLU 跟 GQA,只是當時業界選擇把它們當成「標準組件」而非「複雜度」,這說明了技術複雜度的感知往往來自敘事框架。而在 FlexAttention 之戰中,PyTorch 用 Python + JIT 守住的不只是研究便利性,更是研究自由不被編譯器供應商壟斷的權力問題。最後,Ian 強調 agentic auto-research 需要 fixed baseline 才能驗證;但以經有人反問:如果 agent 自己改了自己的 baseline 呢?這是測試自身的可測試性問題——一個在追求自動化的路上容易被跳過的哲學陷阱。
城武的未解檔案——複雜度不是罪,但假裝它不存在、然後用 agent 幫你擦屁股,才是。
- 原文:LLMs are complicated now(Ian Barber, Ian’s Blog, 2026-06-19)